








 Media Coverage
Media Coverage Press Release
Press ReleaseAbstract
While many business, IT, and data leaders recognize the value of the Databricks Medallion Architecture to implement modern data platforms, its successful execution often remains a challenge. In this whitepaper, we provide a practical roadmap for unlocking business value through the Medallion Architecture using a structured, three-layer design (Bronze, Silver, Gold) that incrementally transforms raw data into trusted, and usable analytics and AI-ready assets. It tackles the pitfalls of “data swamps” through strong governance, automation, and data quality frameworks such as CACTUS (for data quality) and FAIR (for data usability). Featuring a real-world pharmaceutical case study, it illustrates how Databricks capabilities, including Delta Lake, Unity Catalog, and Great Expectations, enable organizations to build scalable, governed, and high-quality data platforms that power Analytics and AI solutions.
1. Introduction
Many organizations today are looking at implementing centralized data platforms like Data Lakes and Lakehouses to drive Analytics and AI solutions at scale. But most of these data platforms are built without clear standards, governance, or quality controls, and have degraded into what is commonly called “data swamps”. Technically, data in data swamps is unorganized (lacking schema enforcement and metadata compliance), untrustworthy (poor data quality affecting operations, compliance, analytics, and AI), hard to use (difficult to find or understand due to poor documentation and adoption), and risky (governance gaps leading to privacy and security compliance issues). While many approaches exist to prevent the emergence of “data swamps,” implementing a modern data platform such as Databricks, Snowflake, or Azure Fabric, provides the structure, governance, and automation needed to ensure that data remains trustworthy, well-managed, and ready for Analytics and AI.
2. Databricks Medallion Architecture
So how can enterprises build a solid data platform? This is where the Databricks Medallion Architecture (also known as the multi-hop architecture) comes into picture. The business
value of Databricks Medallion Architecture is to structure the data pipeline in multiple layers that progressively refine the data by stages, ensuring better data reliability, governance, and reusability. This layered approach ensures that data moves through a controlled and transparent transformation process, improving its trustworthiness and usability at each stage.
However, implementing and maintaining the Medallion Architecture on Databricks (or any similar data platform) can be highly effective, but it also comes with several challenges: both technical and non-technical. The key question for most business, IT and data leaders is how to implement the Databricks Medallion Architecture to drive business value? The value is clear; but the challenge is in execution. In this backdrop, in this whitepaper we offer prescriptive guidance to implement the Databricks Medallion Architecture with a practical a case study from the pharma industry.
“Data lakes will become “data swamps” unless they adopt the disciplined governance and structure typical of a warehouse.”
– Bill Inmon, Father of Data warehousing
Databricks is a data platform to help organizations store, process, analyze, and collaborate on Analytics (Descriptive, Diagnostics, Predictive and Prescriptive) and AI projects (Generative AI and Classical AI). The Databricks Medallion Architecture is a data design pattern to incrementally and progressively improve the structure and quality of data as it flows through each layer of the architecture (from Bronze ⇒ Silver ⇒ Gold layer tables) and turn raw data into trusted and usable data for Analytics and AI [1].
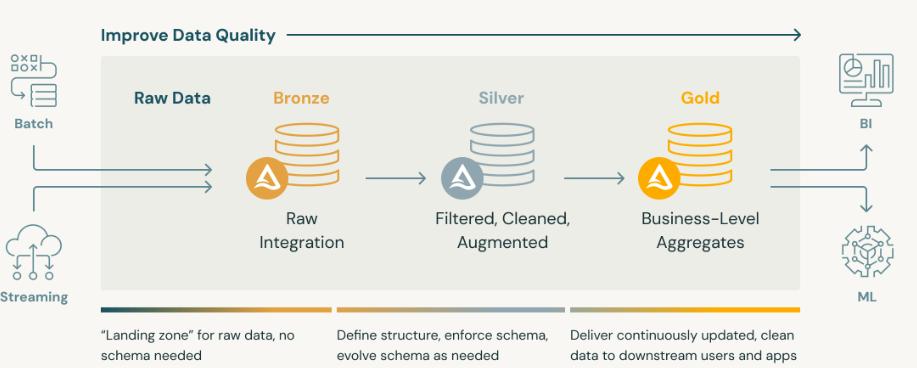
While Databricks explicitly brands the 3-tier data design pattern as the “Medallion Architecture”, most other modern data platforms such as Snowflake, BigQuery, and Microsoft Fabric also recommend a similar 3-tier “raw zone, cleansed zone, and curated zone” model for implementing Analytics and AI solutions. While the tooling, terminology, and ecosystem varies, the core idea is the same – isolate complexity and enable independent and progressive evolution of data for improved business performance. So, the principles discussed here on the Databricks Medallion Architecture is relevant to other data platforms as well.
3. Implementing the Medallion Architecture
Implementing the Databricks Medallion Architecture involves organizing data into three layers—Bronze, Silver, and Gold. Bronze Layer ingests raw data, the Silver Layer transforms and cleanses it, and the Gold Layer delivers curated and useable data for Analytics and AI. The following sections explore each of the three layers of the Medallion Architecture in detail.
Bronze Layer: Raw Data, Staged for Scale
In the Bronze Layer, all relevant data (batch and streaming), is ingested to establish the data foundation. This layer serves as the entry point for raw data in its native format from various source systems, APIs, third-party providers, and more, using the most appropriate data ingestion techniques such as batch ingestion, real-time (or streaming) ingestion, API ingestion, database ingestion (ETL) and more. The data can reside in diverse storage systems, such as NoSQL databases like MongoDB, relational databases like SQL Server, or graph databases like Neo4j, providing flexibility to capture and preserve raw data for further processing.
At this layer, data ingested mirrors the data structure and data values of the source system. In essence, the Bronze layer acts as a stable foundation, storing raw and unaltered data. This layer ensures data completeness so that you don’t lose pertinent data that may be needed later, especially when the Analytics and AI use cases evolve. While working on this layer, the data leaders should ask the following key questions:
- Are we capturing the right mix of business data – internal and external, structured and unstructured, batch and streaming, and more?
- Do we have the scale and performance to handle increasing data volumes?
- Are we collecting metadata to support traceability and auditing for data lineage and data observability?
So, how can enterprises implement the Broze layer? Databricks offers several tools in the Bronze layer. Firstly, the primary data storage layer is Delta Lake, which is essentially a transactional storage layer on top of a data lake, designed to combine the scalability of a data lake with ACID transactional guarantees like a database. Delta Live Tables (DLT) simplify the creation of data ETL pipeline where Databricks Jobs can schedule the data ingestion jobs. DLT controls data quality in the pipelines through based on severity levels – FAIL, WARN, and LOG. FAIL stops pipelines on rule violations, WARN logs warnings, and LOG records issues without interruption. The data is first managed in DBFS (Databricks File System) as it serves as a staging area for the raw data before loading the data into the Delta Lake. Delta Lake provides storage along with schema enforcement and time stamps for the raw data that is getting ingested. Auto Loader manages incremental data ingestion by supporting file formats like JSON, CSV, and Parquet. For real-time data, Structured Streaming enables the ingestion of continuous data streams.
Silver Layer: Trusted, Business-Ready Data
Just because an enterprise has ingested enormous amounts of data in the bronze layer, it doesn’t mean that raw data is ready for Analytics and AI. Most enterprise data is collected primarily for operational and compliance purposes, and not for deriving insights. In general, over 90% of the data in enterprises today is unstructured data [2]. To be useful for Analytics and AI, data must be properly structured, consistent, and contextually labeled [2]. The journey of repurposing data from operations and compliance to Analytics and AI starts from the Silver Layer with deliberate transformation focused on three key shifts:
- Converting raw data into structured data so that data can be easily queried, analyzed, and fed into the data models.
- Labelling, standardizing and formatting data to ensure consistency, and
- Identifying the right variables for data modelling and knowledge graph to capture the semantic meaning.
Unstructured data have no fixed schema. Before this data can populate a database or a Knowledge Graph, it must be processed to identify entities (people, places, products) and relationships, along with normalization, standardization, deduplication, and other cleaning steps. The cleaned data can then be loaded into relational tables, where relationships are often inferred manually or via keys. In a Knowledge Graph, the cleaned entities and relationships become nodes and edges, preserving semantic meaning — not just storing values, but also capturing how things are connected.
Basically, the Silver Layer uses the raw data from the Bronze layer and transforms it into clean data that the business can trust. The trust is built and validated with compliance to data quality “CACTUS” dimensions, such as: Completeness, Accuracy, Consistency, Timeliness, Uniqueness, and Stability.
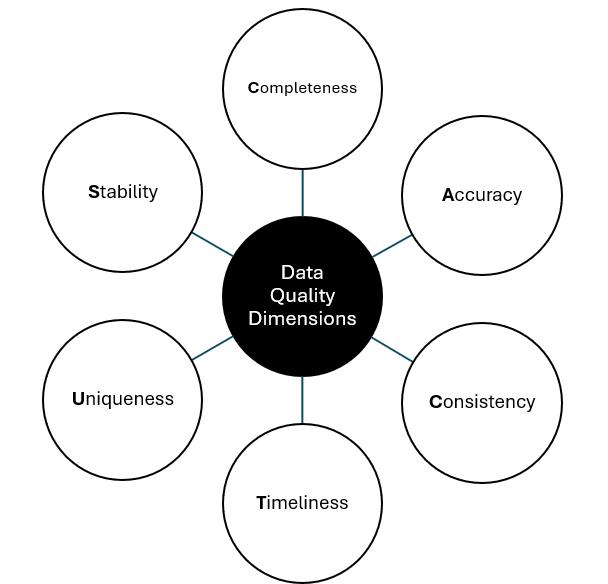
Basically, the Silver layer is where trust or quality in data is built. Achieving data quality is an ongoing process; it is not a one-time effort. It is a discipline that must be enforced consistently at every stage of the data lifecycle. Studies have shown that when data is not governed, data quality degrades by 2 % to 7% every month [2]. While working on this layer, leaders should:
- Establish the CACTUS data quality framework to profile the data and assess the data quality levels on the six key dimensions
- Assign ownership to remediate the data quality issues. Track CACTUS metrics per table per run, publish a scorecard, and make data owners accountable for fixing and improving data quality levels.
- Invest in metadata management and data documentation for improved governance, collaboration, discoverability, and scalability.
Essentially the Silver layer ensures that transformed and structured data can be trusted. Databricks provides several tools to enforce data quality checks on top of the data storage layer. Great Expectations offers excellent features for data validation, allowing you to define complex quality checks on the ingested data. In addition, Soda SQL provides an easy way to define and execute data quality tests using a SQL-like syntax.
Gold Layer: Governed, Ethical, AI-Ready Data
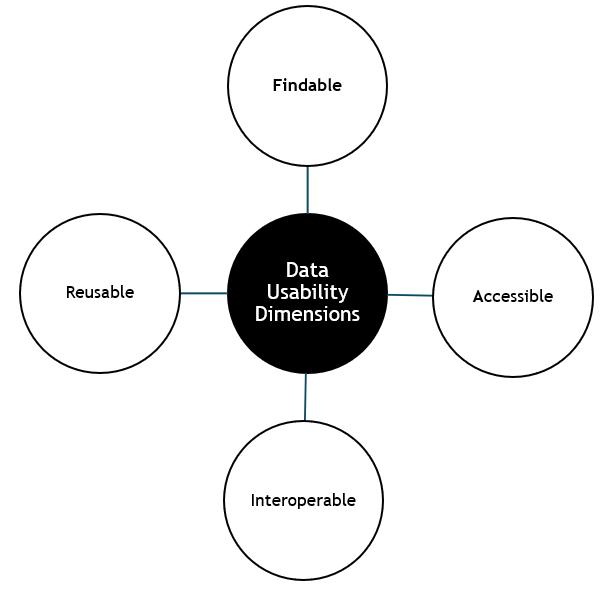
The Gold Layer uses the data from the Silver layer and serves highly curated data products that are modeled around business entities such as customers, sales, general ledgers, products, and more. The Gold layer is where data is made usable by implementing the FAIR principles:
- Findable: Data is easily located by humans and systems
- Accessible: Data is secure, and data access is simple
- Interoperable: Data works across platforms and tools
- Reusable: Data is structured for reuse
Technically, the Gold layer is de-normalized and read-optimized with fewer joins. While working on this layer, leaders must:
- Integrate data governance teams early in data product design to proactively address compliance risks, minimize delays, and ensure that data products are factors security and regulations.
- Use metadata catalogs, open formats, and secure APIs to make the quality data FAIR.
- Champion data governance and invest in data stewardship roles with an owner, SLA, versioned schema contract, documented dimensions/measures, lineage, usage examples, and access policy.
- Expose BI-friendly star schemas and aggregate tables; implement row and column-level data security.
Databricks provides a suite of powerful tools to implement the Gold layer. Unity Catalog ensures that Gold layer data is governed, accessible, and secure. It provides fine-grained access controls, allowing administrators to define precisely who can access what data, down to the column level if needed. In addition to access control, Unity Catalog offers centralized data governance capabilities and automated data lineage tracking, giving full visibility into where data originates, how it flows through the system, and how it’s transformed. By leveraging Unity Catalog within the Databricks platform, organizations can ensure that the right users and systems have timely, secure, and compliant access to data.
“The Medallion Architecture progressively refines raw data into trusted, high-value assets, by bridging the gap between engineering efficiency, governance, and actionable insight.”
– Sreenivas Gadhar,
Vice President, Data and Analytics – Engineering and Delivery,
Global Insurance Brokerage and Risk Management Company
Overall, when properly implemented, the Medallion Architecture delivers a single source of truth for Analytics and AI. By organizing data into Bronze (raw), Silver (cleaned), and Gold (usable) layers, businesses can increase the confidence for data usage across multiple use cases. The three layers or phases of the Databricks Medallion Architecture discussed above is as shown below.
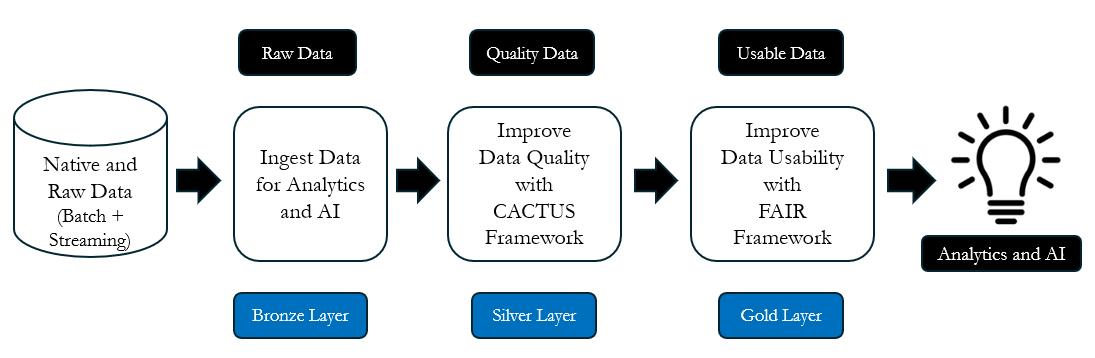
4. Case Study: Implementing the Medallion Architecture in a Pharma Company
A global pharmaceutical company was struggling to derive actionable insights from the data sought our help to implement the Databricks Medallion Architecture on AWS S3. The data existed across multiple IT systems such as lab systems, commercial systems, EDC (Electronic Data Capture), regulatory databases, and more. The data was inconsistent, poorly labeled, and difficult to trust or reuse. This hindered key business goals such as speeding up clinical trials, ensuring regulatory compliance, and supporting AI-driven drug discovery.
Step 1: Ingest Raw Data
In implementing the Bronze layer, the raw data from clinical trial systems, lab instruments, and patient registries was sourced and ingested. As the data was mostly in structured format, the data was stored in Delta Lake on AWS S3 as it provided ACID transactions, schema enforcement, versioning, and time travel capabilities on both batch and streaming data
Given the relatively modest data volume (in the range of terabytes), we adopted lightweight data formats such as CSV and JSON. These data formats provided ease of use and flexibility during ingestion, making them preferable over more heavyweight formats like Apache Parquet, which are better suited for petabyte-scale, columnar analytics. AWS Glue, a fully managed ETL service, was used to ingest batch data, and Apache Kafka, was leveraged for ingesting real-time data feeds. Once ingested, raw data persisted in the Delta Lake. Guardrails were established across Databricks clusters, jobs, workspaces, and SQL Warehouses for data governance. In addition, compaction strategies ensured Delta files were maintained in the optimal range (128MB–512MB) and frequently queried columns were Z-ORDERed to accelerate query performance. VACUUM retention policies were applied to manage storage costs without compromising recoverability, and low-cardinality partitioning was used to avoid excessive small files while enabling efficient pruning.
Step 2: Validate Data Quality Using CACTUS Framework
In a pharmaceutical environment, ensuring the data quality is critical for analytics, regulatory compliance, patient safety, scientific rigor, and more. To build data trust, we embedded the CACTUS data quality framework on the raw data that was ingested:
- Completeness: Ensured all key clinical fields such as demographic data, adverse events, dosage, and more were populated.
- Accuracy: Cross-referenced lab values with known physiological ranges.
- Timeliness: Monitored latency between clinical site data entry and central ingestion.
- Other dimensions such as Consistency, Uniqueness and Stability were also tracked and addressed through automated alerts and remediation workflows.
In addition, comprehensive data quality checks were carried. With Delta Live Tables (DLT), the team was able to define rules and enforce severity levels i.e. FAIL, WARN, and LOG, that control data pipeline behavior based on the quality of incoming data. This allowed for early detection and handling of anomalies before data propagated downstream. Great Expectations executed complex validation checks such as null constraints, uniqueness, statistical profiling, and distribution checks. This helped ensure that transformed data adhered to pharma specific standards such as dosage formats, unit consistency, timestamp and completeness). Soda SQL was introduced to help data stewards and data analysts run Analytics workloads.
Although knowledge graph databases like Neo4j or AWS Neptune were considered for representing entities and their relationships, Delta Lake was chosen instead. Its support for SQL tables and dataframes made it suitable for reporting, dashboards, and model training, particularly given that the ingested data was primarily structured and semi-structured.
Step 3: Apply FAIR Principles for Data Usability
Using the FAIR framework on the trusted data, we made its data usable for Analytics and AI with:
- Findable via metadata catalogs that indexed all clinical, lab, and patient data.
- Accessible through governed APIs and secure notebooks for data scientists.
- Interoperable using open standards such as HL7 FHIR and CDISC SDTM.
- Reusable through standardized data models and clear usage policies.
Here, the Databricks Unity Catalog was used for fine-grained access controls, data lineage tracking, and centralized governance. With data lineage, the firm could trace outputs back to raw inputs, enabling full auditability. Great Expectations was also used here for further validating the Gold-layer datasets for accuracy, completeness, and consistency before being exposed to end-users, where Databricks SQL was used for building reports and dashboards.
Table below categorizes the activities by Bronze, Silver, and Gold layers, aligned to the Databricks Medallion Architecture and the pertinent Databricks products.
| Databricks Tool | Layer | Key Activities |
| Delta Lake | Bronze | Delta Lake is a data storage and management layer. |
| Delta Live Tables (DLT). | Bronze | DLT simplifies the creation of data pipeline where Databricks Jobs can schedule the data ingestion tasks. |
| Databricks Jobs | Bronze | Scheduling and orchestration of data pipelines for data ingestion. |
| DBFS (Databricks File System) | Bronze | DBFS is the staging area for the raw data before loading the data into the Delta Lake. |
| Delta Lake. | Bronze | Delta Lake provides storage along with schema enforcement and time stamps for the ingested raw data |
| Structured Streaming | Bronze | Structured Streaming enables the ingestion of streaming data. |
| Auto Loader | Bronze | Auto Loader manages incremental data ingestion by supporting file formats like JSON, CSV, and Parquet. |
| Great Expectations | Silver and Gold | Great Expectations offer powerful frameworks for data validation, allowing you to define complex quality checks. |
| Soda SQL | Silver and Gold | Soda SQL provides an easy way to define and execute data quality tests using a SQL-like syntax. |
| Unity Catalog | Silver and Gold | Central data governance and access control. |
To summarize, the Databricks Medallion Architecture based on the CACTUS data quality and FAIR data usability frameworks supported with pertinent Databricks tools offered a robust data platform for Analytics and AI, thereby helping the firm derive better insights for improved business performance.
5. Final Thoughts: Data as a Strategic Asset
The Medallion Architecture is a pragmatic, layered design pattern with three main layers -Bronze (for data ingestion), Silver (for data trust), Gold (for data usability) to power Analytics and AI ready. While rooted in the Databricks ecosystem, its layered approach i.e. Bronze, Silver, and Gold, is equally applicable across modern data platforms such as Snowflake, BigQuery, and Microsoft Fabric. However, the architecture’s value is realized only through effective adoption. Success requires more than scalable technical infrastructure; it demands strong data literacy and cross-functional collaboration between data, IT, and business teams. Investing in data literacy, governance, and team enablement is just as important as investing in the platform itself. Overall, Databricks data platform should be treated as a living system; one that evolves with your business. The Medallion Architecture is not just a technical decision; it is a strategic commitment to building a data-driven culture for driving measurable business impact.
6. References
- Southekal, Prashanth, “Data Quality: Empowering Businesses with Analytics and AI”, John Wiley, 2023

